
Based on https://www.youtube.com/watch?v=eDkE4WNWKUc
Traditional K8s Scheduler uses predicates (hard requirements) and priorities (soft requirements)
As K8s has evolved now these requirements are placed into scheduler framework with scheduling plugins (callbacks) this consists of a series of steps.
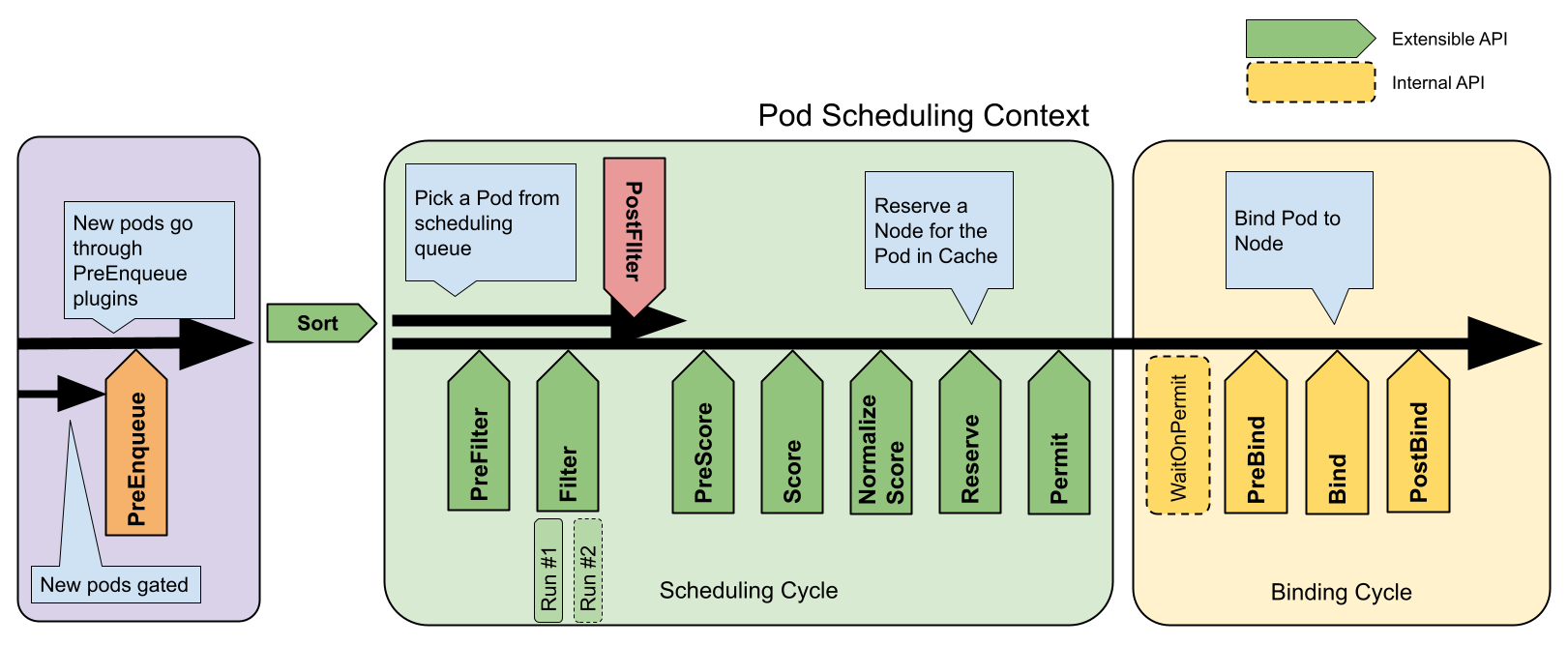
Here’s the full set of configurable plugin extension points in the Kubernetes scheduler:
| Plugin Extension Point | Purpose | Can Be Configured in KubeSchedulerConfiguration? |
|---|---|---|
| PreEnqueue | Runs before adding a pod to the scheduling queue. | ✅ Yes |
| PreFilter | Runs before filtering nodes, allows modifying pod state. | ✅ Yes |
| Filter | Determines if a node is suitable for a pod. | ✅ Yes |
| PostFilter | Runs when no nodes are viable, can implement preemption. | ✅ Yes |
| PreScore | Runs before scoring, allows modifying scoring logic. | ✅ Yes |
| Score | Assigns scores to nodes. | ✅ Yes |
| NormalizeScore | Adjusts node scores before final selection. | ✅ Yes |
| Reserve | Temporarily holds a node for a pod. | ✅ Yes |
| Permit | Approves/rejects a pod before binding. | ✅ Yes |
| WaitOnPermit | Waits for external approval before proceeding. | ✅ Yes |
| PreBind | Runs just before binding a pod to a node. | ✅ Yes |
| Bind | Actually assigns the pod to a node. | ✅ Yes |
| PostBind | Runs after binding is complete. | ✅ Yes |
Preenqueue plugin returns success if the pod is allowed to enter the active queue. If failed it places pod in an internal unschedulable pods list but it is retried later.
As you can see here there is two separate go routines so these phases can be handled in parallel. One for scheduling (filtering and scoring) and another for binding.
Sorting allows you to change the pods you get from the queue for scheduling.
Binding includes a permitting step (like only allow scheduling once some condition is met, this is used for gang scheduling for example).
Filtering is split into three stages. One for pre-filter to optimize scheduling by eliminating unavailable options from the start. One for post-filter this happens after schedule has been made to make further adjustments or corrections. For example removing overlapping appointments or take in additional constraints that weren’t considered initially.
Applying Scheduler Plugins
In order to apply any custom scheduler plugins, you need a custom scheduler build. This is done by compiling the scheduler with your custom plugin (e.g. go build -o custom-scheduler ./cmd/kube-scheduler) Then deploying the custom scheduler as a pod.
Pod affinity and antiaffinity are rules for how to schedule pods based on other pods. They can either be imposed (hard like predicates) with requiredDuringSchedulingIgnoredDuringExection or (soft like priorities) preferredDuringSchedulingIgnoredDuringExection. Preferred would take a weight value into account for how strong a preference there is. There is also requiredDuringSchedulingRequiredDuringExection which requires conditions to be ensured both during the scheduling process as well as even after once the pod is scheduled, it needs to be kept.
There is also node affinity and antiafinity which are rules for how to schedule pods based on nodes.
Each affinity has a topology associated with it, which determines the level of affinity:
- “kubernetes.io/hostname” → Applies at the node level
- “topology.kubernetes.io/zone” → Applies at the zone level
- “toplogy.kubernetes.io/region” → Applies at the region level
Apart of affinities there is topologySpreadConstraints - these determine how to spread pods across nodes. For example
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: "ScheduleAnyway"
labelSelector:
matchLabels:
app: web # Applies to pods with label web
containers:
- name: nginx
image: nginxmaxSkew: 1 means difference between most and least populated nodes can be at most one
Daemonset controller just sets the node affinity on the pod and then leaves it up to the scheduler to schedule the pod
Pod Overhead Pods may have additional system beyond just the application resources it specifies (extra resources not part of the container spec). For example if running in a sanboxed environment like kata you need additional resources to run this environment. So to account for this you can set a runtimeclass with overhead like
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-containers
handler: kata
overhead:
podFixed:
cpu: "250m"
memory: "64Mi"And then apply the runtimeclass to a pod
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
runtimeClassName: kata-containers
containers:
- name: app
image: nginx
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "1000m"
memory: "256Mi"This overhead is applied/added to each pod scheduled with the runtime class specified
In-place update of pod resources - this is a proposed feature which you can enabled via feature gate for in-place increase of pod resources.
Multiple Schedulers
We can define all our schedulers in the KubeSchedulerConfiguration e.g.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: "default-scheduler"
plugins:
filter:
disabled:
- name: "NodeResourcesFit" # Disable NodeResourcesFit for default profile
- schedulerName: "custom-scheduler"
plugins:
filter:
enabled:
- name: "NodeResourcesFit" # Enable it for the custom profileor
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: "default-scheduler"
pluginConfig:
- name: "MyCustomPlugin"
args:
enableForPodsWithAnnotation: "custom-scheduling=true" # Only applies to Pods with this annotationIf you enable multiple schedulers, each scheduler is a separate controller. Then in your podspec you specify the schedulerName like so:
apiVersion: v1
kind: Pod
metadata:
name: custom-scheduler-pod
spec:
schedulerName: my-custom-scheduler
containers:
- name: app
image: nginxIf no scheduler specified then default kube-scheduler is used. Running a custom scheduler as a pod is the most common approach.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-custom-scheduler
spec:
replicas: 1
selector:
matchLabels:
component: my-custom-scheduler
template:
metadata:
labels:
component: my-custom-scheduler
spec:
containers:
- name: scheduler
image: my-scheduler-image
command: ["my-custom-scheduler", "--config", "/etc/scheduler/config.yaml"]If pod doesn’t have a matching scheduler. Like if a schedulerName is specified that doesn’t exist, the pod remains unscheduled forever.
Cluster Autoscaler uses scheduler inbuilt. Which is why for say kubernetes 1.16 release CAS version needs to be 1.16 as well because it uses the scheduler from upstream. It is important it does this because CAS needs to determine if the number of nodes its creating is enough for the number of pending pods - so it uses the filtering mechanisms for example to determine this.
Descheduler Default scheduler doesn’t care about pods once they are scheduled. If descheduler sees pods not conforming to scheduling constraints anymore you can evict those pods (note it doesn’t reschedule them it leaves that up to the scheduler to do). However it can even evict pods under other constraints like pods having too many restarts or pods violating (pod or node) affinity rules. This could happen when say new nodes join the cluster.
Create Configmap for Descheduler Policy
apiVersion: v1
kind: ConfigMap
metadata:
name: descheduler-policy
namespace: kube-system
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
RemovePodsViolatingNodeAffinity:
enabled: true
RemovePodsHavingTooManyRestarts:
enabled: true
params:
podsHavingTooManyRestarts:
podRestartThreshold: 3
RemovePodsViolatingInterPodAntiAffinity:
enabled: true
Deploy descheduler as a CronJob
apiVersion: batch/v1
kind: CronJob
metadata:
name: descheduler
namespace: kube-system
spec:
schedule: "*/10 * * * *" # Runs every 10 minutes
jobTemplate:
spec:
template:
spec:
serviceAccountName: descheduler-sa
containers:
- name: descheduler
image: registry.k8s.io/descheduler/descheduler:v0.26.0
command:
- "/bin/descheduler"
- "--policy-config-file"
- "/policy-dir/policy.yaml"
volumeMounts:
- name: policy-volume
mountPath: /policy-dir
volumes:
- name: policy-volume
configMap:
name: descheduler-policy
restartPolicy: NeverCluster role attaches a service account to a cluster role
apiVersion: v1
kind: ServiceAccount
metadata:
name: descheduler-sa
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: descheduler-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: descheduler-rolebinding
subjects:
- kind: ServiceAccount
name: descheduler-sa
namespace: kube-system
roleRef:
kind: ClusterRole
name: descheduler-role
apiGroup: rbac.authorization.k8s.ioResource requests and limits are degined at the container level not the pod level. Kubernetes adds up container requests to determine pod scheduling requirements.